

Unless you have been living under a rock, you would have surely seen the 10-year challenge that is populating our Facebook and Instagram timelines. Participating in the challenge means you need to share two of your photos, taken 10 years apart—one from the year 2009 and one from now, the year 2019. Within just the realms of it being a fun thing to do, these comparative images do usually show up a rather interesting contrast reflecting how most of us have changed, at least visually, over the 10-year period. But as with most things Facebook these days considering all the data breaches and the secretive liberties with user data over time, it is perhaps only logical that there is a healthy sense of suspicion about this 10-year challenge. This surely can’t be an elaborate plot to tell us what we already knew—we are getting old, and ten years is a long time.
The Cambridge Analytica scandal from last year, and the subsequent data breaches, are still fresh in the minds of users, globally. On its part, Facebook has come out with a clarification that it has had nothing to do with the 10-year challenge trending on social networks such as Facebook, the Facebook-owned Instagram and even Twitter, for that matter. “The 10 year challenge is a user-generated meme that started on its own, without our involvement. It’s evidence of the fun people have on Facebook, and that’s it,” says the social network, in an official statement. It is important to weigh both sides—does Facebook really even need this data? And if yes, why? Or is alleging that Facebook is behind this is as ludicrous as saying something on the lines of how Google may be spying on us just because our Android phones have a microphone for voice calls?
Does Facebook really need this data?
Back on 30 April 2009, Facebook has said that as many as 15 billion photos had been uploaded by the users on the social network, already. And as many as 220 million new photos were being added every week. That’s 15 billion at some point in the year 2009. In the year 2013, users were uploading as many as 330 million photos a day. A day. We need to keep our eyes on the fact that smartphone penetration, Facebook usage and the willingness to upload photos online have all increased tremendously since then. We are in 2019 now, and it is impossible to know exactly how many billion or trillion photos Facebook currently has—unless they tell us. Which is unlikely. But we digress. Back to the point, and along the way, image processing algorithms, powered by artificial intelligence (AI), have only become even smarter. Almost every company is using facial recognition in one way or the other. The Photos app on your Apple iPhone can do facial recognition. The Google Photos app on your Android phone understands and matches faces to people and contacts. Its everywhere. As with most things on the internet, all data is good data. The more data, the merrier. “#Facebooks 10 Year Challenge, best way i have ever seen to train their AI in face recognition with your personal data,” says Thomas Tscherisich, SVP Internal Security at Deutsche Telekom, in a tweet.
All data is good, but why does Facebook need this?
Simple. All of this data could be mined to train facial recognition algorithms to better understand changes in facial structure, contours, skin colour and ageing. Simply put, most people show significant differences in how they look if one is to consider a 10-year period. That helps AI learn better the fine art of age progression in humans. “Let's just imagine that you wanted to, say, train a facial recognition algorithm on age-related characteristics. You'd ideally want a broad and rigorous data set with lots of people's pictures. It'd help if you knew they were taken a fixed number of years apart — say 10 years,” says Kate O’Neill, author of Tech Humanist, in a tweet.
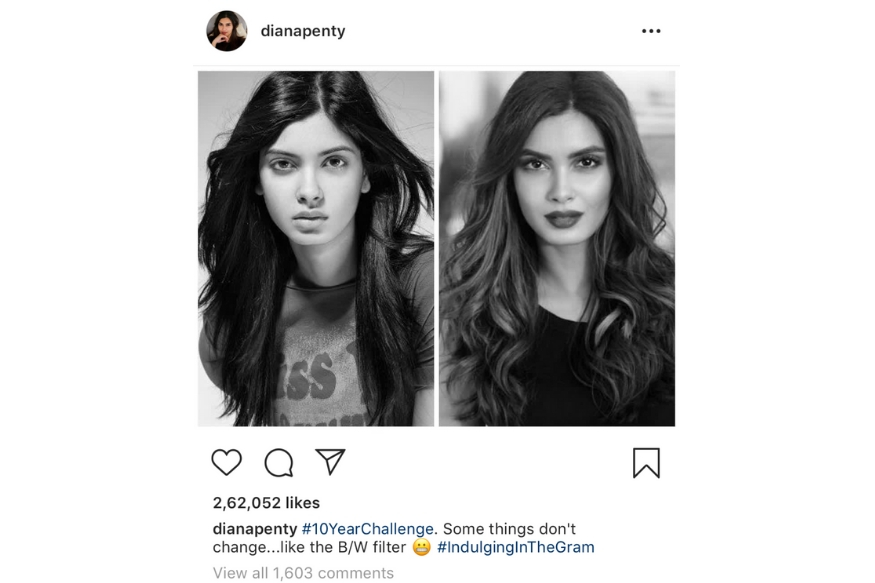
There is never a good or bad time to hone the skills of the artificial intelligence algorithms that power your systems. Whether Facebook flagged off the 10-year challenge or not, this could help it tremendously. To perfectly train a facial recognition algorithm, the larger the sample size, the better. And by larger, we are talking about billions of images. Ask Google, and they will tell you how much effort went into making the Google Photos algorithms as robust as they are right now. In fact, if you use an iPhone, you would have surely noticed the “People and Places” section in the Photos app—it regularly asks you to confirm additional photos of specific people, to better understand different expressions, age and more. What better way to train a facial recognition algorithm on how humans age, than by feeding it photos of the same humans, exactly 10 years apart? The “perfect storm for machine learning," is how Amy Webb, a professor at NYU Stern School of Business, described this to CBS News.
Is Facebook smartly making users sift the data for them?
As we have said before, if this is true, then it is a purely genius move. User preferences have changed significantly over time. Perhaps 10-years ago, Facebook and social media users in general were not uploading enough photos of themselves, but perhaps sharing photos of pets, food and travel more. Along the way would have been a large chunk categorized as ‘throwback’. A lot of the uploads may have been done in a staggered fashion, and the metadata isn’t always enough to accurately train AI algorithms—basically, they aren’t always chronological. Now, the same users are logging in and uploading the old and the new, the before and the after images. Facebook is getting the exact timestamps for these images. Social media users are pretty much sorting out their old images, clearly marking out their photos. On a platter, so to say.
What it stands to gain?
Apart from an even larger data set to play with, Facebook will be able to use this data further improve the algorithms. And with this newly compiled data, what it’ll help the most is with targeted advertising. Messaging for advertising will be modified for you based on a lot of characteristics as we go along, and visual characteristics might just become one important criterion too. Tie that in with location tracking, our likes and interactions, and the digital profiling goes well beyond just knowing your name, who your friends are and what you like to eat.
As we leave you to ponder on this, it is perhaps timely to remind you that the Facebook has, for long, had a feature that lets the social network do facial recognition scans on your friend’s photos and detect as well as notify you if you are detected on any of them, but aren’t tagged. You have the option to turn this off in the app. But in the world of social media, where data is money and the user is the product, is off really off?














Comments
0 comment